


FOR A NON-AGRESSIVE and RESPECTFUL AUDIO MASTERING! (2)
The MIXING source
The analysis of the file shows us a regular progression of the average level (RMS) via 3 steps (beginning, middle, end), from ≈ -26 dB to ≈ -14 dB, that is to say 12 dB of difference between the beginning and the end of the song.
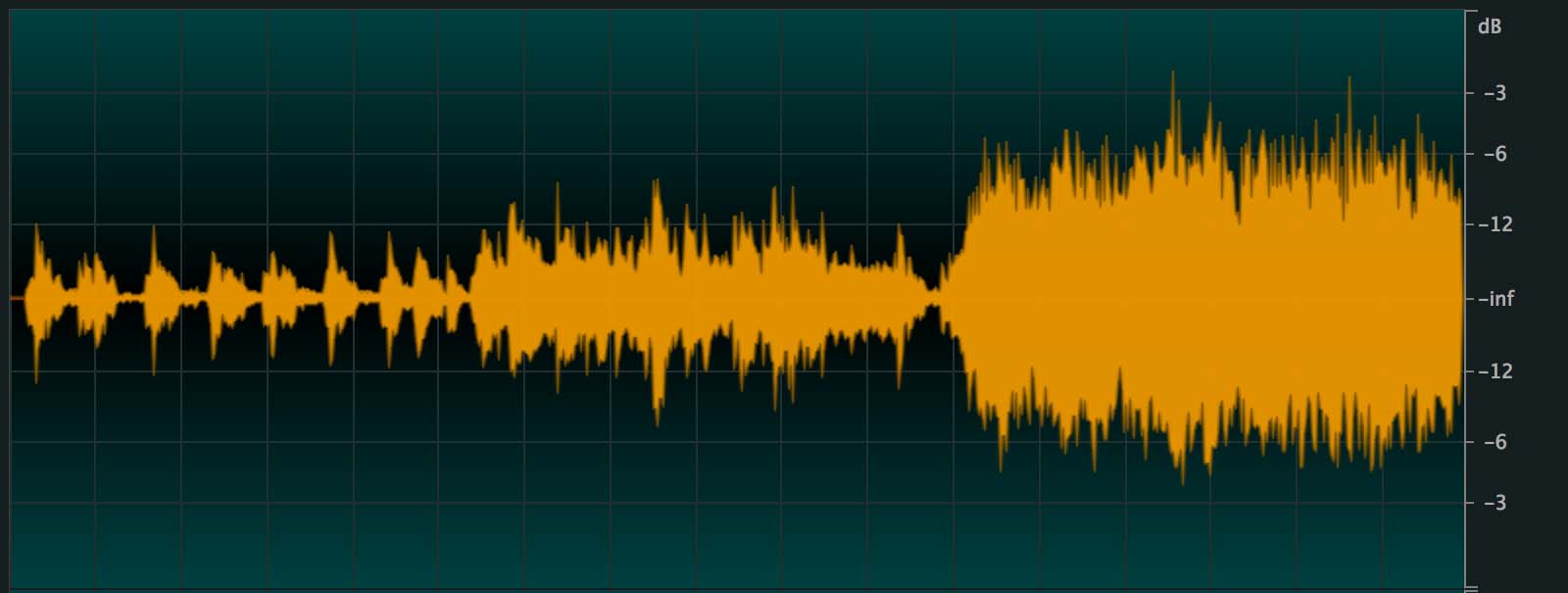
click on the image to enlarge it
The "current" MASTERING
We find the same progression of the average level (RMS) - in 3 steps - from ≈ -17 dB to ≈ -6 dB, or 11 dB difference between the beginning and the end of the song.
Very surprisingly : the gain of +1 dB is without real interest. Only the "global" average level went from ≈ -17 to ≈ -9 dB, meaning a "displacement" of +8 dB, which would have been strictly the same if you had simply turned up the listening volume !
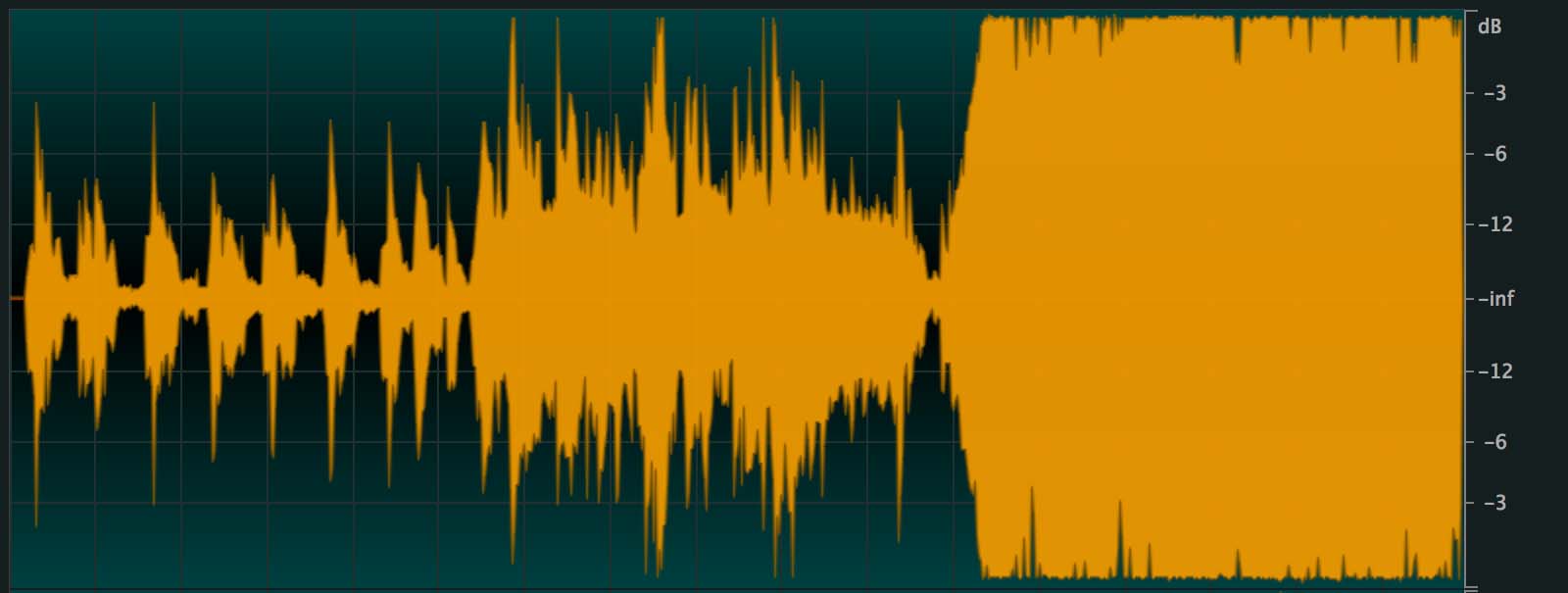
click on the image to enlarge it
Nothing very annoying in itself ... except that this +8 dB gain was achieved at the expense of the quality of the music, because there was only 2 dB of margin (peak vs 0 dBFS) on the mix file.
How this gain of ≈ +8dB has been realized ? ... by a strong limitation of peaks (see other article here).
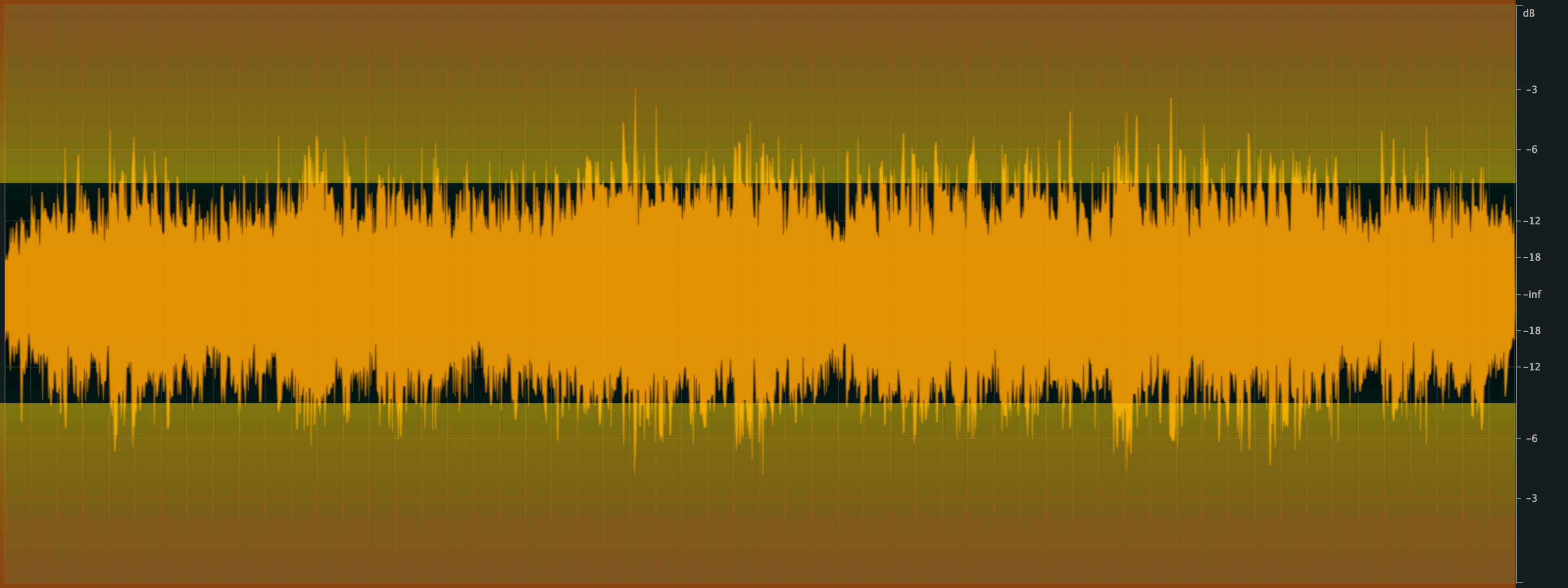
click on the image to enlarge it
How is this negative? If there had been very few peaks, the audible impact would have been imperceptible. Unfortunately, for this third part of the song (≈ 1/3 or about 1 min) it represents a good part of the useful signal! So, the limitation applied "cuts off » to the necessary musical information from the « intense » moment, and as a direct consequence on the "imprecise-aggressive" side that we find in a comparative listening [ Mastering source (same RMS level as the mix) ].
To quickly illustrate the damage, you can also listen to the "muted" signal [ Signal removed trought Peak Limitation Mastering ]. This is far from insignificant !
WHY « SO MUCH HATE » ?
To tell the truth, I don't know !…
Between a lack of attentive listening, ignorance of the consequences (or ... ???) ... There are several possibilities!
Why don't we simply realize an optimized "compression" of the whole work and thus bring the difference between the beginning (low level) and the end (high level) to an amplitude interval which would be easier to listen to in motion ?
Perhaps it is because the vast majority of compression solutions tend to "mute/soften" the sound a little and reduce the width of the stereo image (difficult to quantify, but a reality in comparative listening).